Hi team,
Every one of my submissions failed this week’s out-of-sample scoring with the same error. After going through the run logs, the cause is a change to the dataset’s feature schema that — as far as I can tell — wasn’t communicated in advance.
What happened
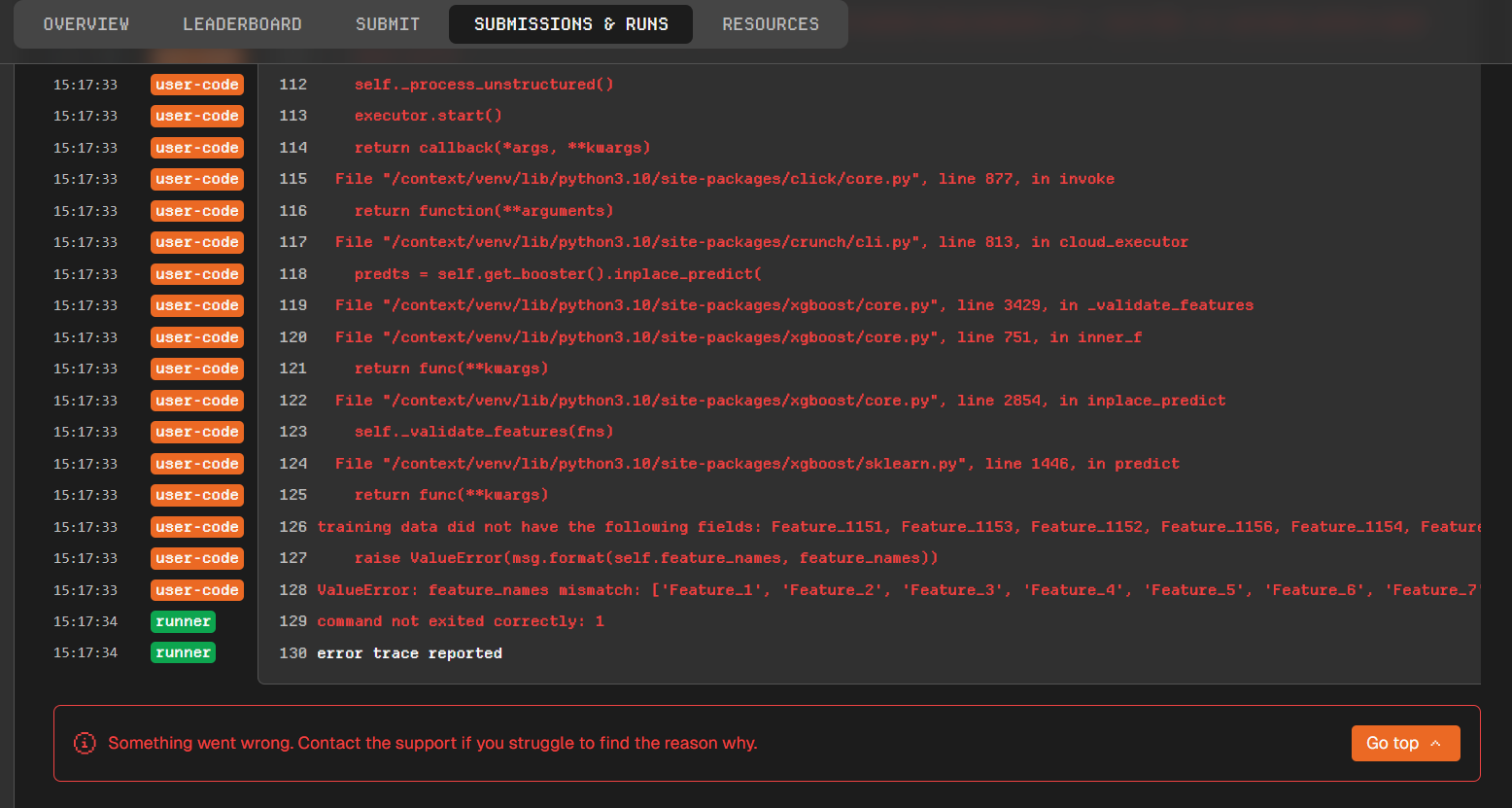
All of my models errored during infer with an XGBoost feature-name mismatch:
ValueError: feature_names mismatch: [...]
training data did not have the following fields:
Feature_1151, Feature_1152, Feature_1153, Feature_1154, Feature_1155, Feature_1156, Feature_1157
This week’s data release (data-releases/240) ships 1157 raw Feature_* columns instead of 1150 — seven new features (Feature_1151–Feature_1157) were added. The original 1150 features are all still present, so it’s a purely additive change.
Why it breaks
Following the documented convention, my code selects features with column.startswith("Feature_"). That now sweeps in the seven new columns and feeds them to models that were trained before those columns existed, so XGBoost rejects them at predict time. This hit every model I’ve submitted — all of which scored cleanly in previous weeks. Nothing on my side changed; the input schema changed underneath the existing submissions.
Impact
All my submissions for this scoring cycle failed and (as far as I can tell) produced no score for the week.
Questions
-
Was this feature addition announced anywhere ahead of time? I couldn’t find any notice — if one exists, please point me to it.
-
Going forward, where will feature-set / schema changes be communicated, and how much advance notice will participants get?
-
Will additive feature changes come with a backward-compatibility or transition window so that already-submitted models don’t break silently?
-
Given the lack of notice, will affected submissions for this cycle be re-scored or exempted from any ranking/reward penalty?
Happy to share full run logs and submission IDs (e.g. 56135, 49572, plus the rest) if that helps support reproduce it. Thanks.