Part 1: DataCrunch Migration Proposal
Following the recent DataCrunch (DC) Rally, we are preparing to migrate DC dataset from the legacy platform to the new infrastructure. This post is an official proposal and will be voted on during the upcoming week. Please read carefully.
“Belief in the wisdom of the crowd necessitates the empowerment of each member. Although we are confident in the migration assumptions, we seek community confirmation through this crunch proposal. Please vote according to your convictions” — Crunch.Capital
Migration Objectives
- Ensure a smooth transition from V1 to V2 without disrupting current submission pipelines
- Use the migration as an opportunity to enhance DC reward distribution.
- Simplify the system to support multi-model submissions without compromising quality. Because who doesn’t love a good model ménage à trois? ^^
1. Transition from Ongoing to Resolved Target Scoring
Previous Method: Scoring was conducted daily on ongoing targets rather than at target resolution. Like trying to score a soccer player before the match ends! This method diluted the accuracy of predictions and reward distribution by equally weighting daily outcomes. For instance, if Apple significantly outperformed Microsoft on the last day of the month, your model even if correct would have only receive 1/30 of the reward. Who want to receive only 1/30 of ice cream when right?
New Approach: Evidence supports scoring based on resolved targets, re-aligning with model training and scoring.
Accurate, fair, and no daily ice cream rationing…
2. Rolling Leaderboard Changes
Previous System: Rewards were distributed based on a rolling average of 12 weeks across all active targets. Only one model submission was allowed, leading to suboptimal performance across different prediction horizons.
No model could perform across all prediction horizon (30 days, 60 days and 90 days)
Proposed System: Separate rewards per target to reflect specific model performance. Allow multiple model submissions, enabling specialization for different prediction horizons. Longer horizons will yield higher rewards due to better returns and Sharpe ratios observed during last year OOS.
3. Tailor-made rewards for tailor-made models.
Before:
- $120,000 paid on the average score of each target (Spearman Corr.)
After:
- $60,000 yearly on target B (Spearman Corr.) + $10k bonus for cumulative alpha. (A little something extra for that alpha magic).
- $20,000 yearly on target G (Spearman Corr.),
- $20,000 yearly on target R (Spearman Corr.),
- $10,000 yearly on target W (Spearman Corr.).
4. Multi-Model Submission
- Four model slots will be available for submission aligning model slot with number of target. We don’t want to turn into a Las Vegas Casinos.
- Encourage submissions on the platform for efficient scaling and management.
- DC covers compute costs, and the platform supports deployment, triggering, and retraining at no cost for the crunchers. (Crunchers are basically GPUs rich
 — One benefit of working for hedge funds)
— One benefit of working for hedge funds)
5. Score Scaling
- Previous reward scaling was necessary due to the different scale of spearman in each dataset.
- With a unified Master dataset, this step is now redundant and will be eliminated. One dataset rule them all!
Part II: DataCrunch Rally — Breaking down iteration.
Introduction:
In our previous Rally, DataCrunch aimed to test a series of internally successful assumptions. However, without confirmation from the broader community, there’s a substantial risk of overfitting. Below, we detail the tested assumptions and the findings from this iteration.
A. New Metric
Initial Findings: Historical tournament predictions showed an 84% correlation between cumulative alpha score and cumulative returns Out-Of-Sample. This inspired the proposal of Cumulative Alpha Score as a metric to finally reconcile the training metric with the pursuit of idiosyncratic returns. On top of that the Orthogonal API was Designed to help build models that can distinguishing beta from alpha within the model training loop. This allows differentiation between crowded and novel insights at the modelling stage and avoiding rediscovering common sources of return in a fancy way.
Current Results: In the Rally submissions, the correlation between cumulative alpha score and cumulative returns dropped significantly to 22%. This stark contrast suggests a potential invalidation of our initial assumptions regarding this metric.
B. Post-Processing Variations
Historical Process: Previously, post-processing involved Gaussian quantization of features into five bins and shape-based quantization of targets.
Rally Adjustments:
- Target: Adjusted target quantization to fit the real distribution of returns for target_w. Other targets were quantized in a Gaussian way.
- Feature: Added a Gaussianization step before and after orthogonalizing features against industry exposures. More Gaussian than a math professor’s dream.
Findings: Comparative analysis invalidated the orthogonalization of features with industry exposure making the gaussianizations steps not necessary. Although theoretically sound for an industry-neutral portfolio, arbitrary orthogonalization of features destroyed significant information in the dataset. Regarding targets, the proposed post-production doesn’t seemed to impact results.
C. New Target
Rationale: The new target aimed to realign with theoretical principles, aligning portfolio rebalancing frequency with prediction horizon.
Issues: The 7-day raw return target proved suboptimal due to high noise levels. Try to hear the flute in a middle of a rock concert…
Legacy Tournament Insights: Long-term targets yielded better results with the current data generating process out-of-sample. Aligning targets with consistent alpha observed in the system, rather than arbitrary portfolio rebalancing, seems to be a much better solution.
Conclusion: The recent experiment reinforced the preference for longer-term targets with the current dataset. Despite the existence of shorter-term alpha, the current strategy favors low turnover alpha, thus higher rewards with longer-term targets proposed for the migration. Slow and steady wins the alpha race.
D. Participant Count
Observations: The Rally had a low number of participants. Despite this, we believe in the quality of the participation. However, more statistically significant number of submissions would facilitate conclusions.
Conclusion: Future iterations will include smaller rallies and less changes for A/B testing purposes only.
E. Historical vs. Rally
Maximizing the Spearman correlation on a 90-day target results in more stable “alpha portfolios” compared to training on shorter-term targets. We suppose that the decoupling of cumulative alpha scores is due to the noisier short-term targets and the process of feature orthogonalization. The following graph demonstrates that historical predictions outperform rally predictions both out-of-sample.
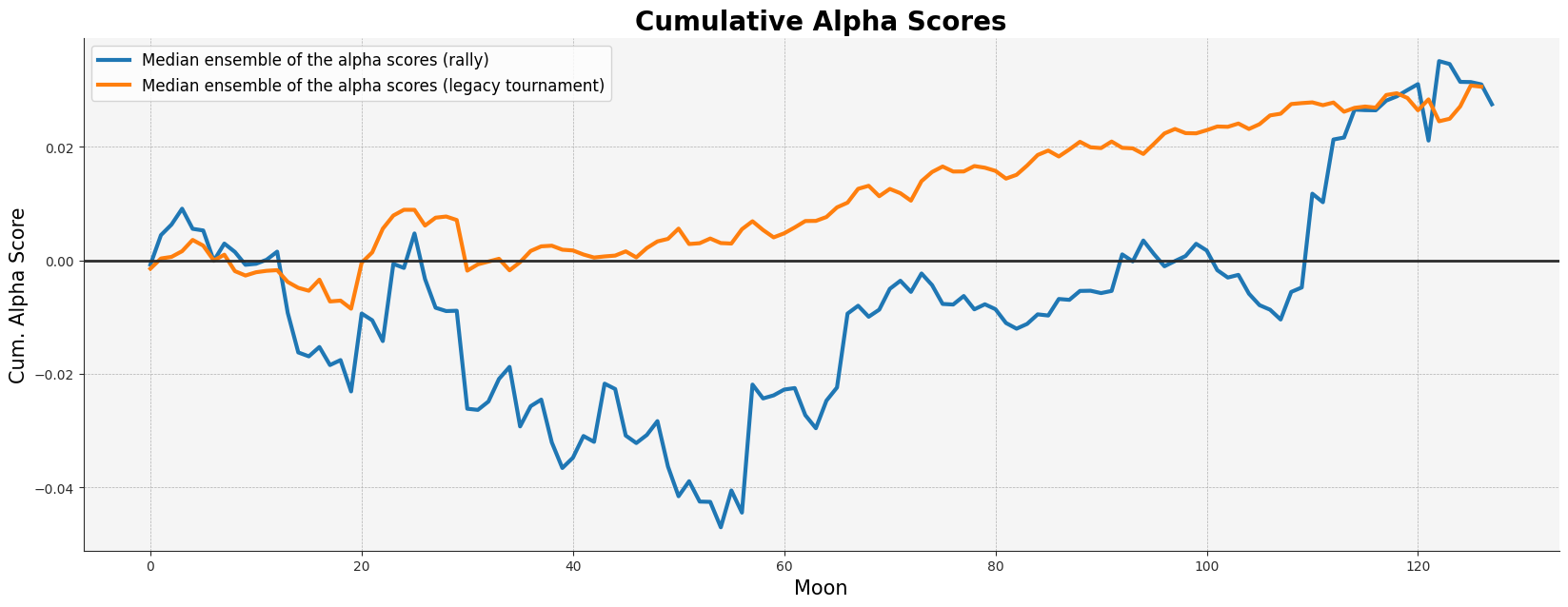
We value your participation in iterating on the DataCrunch master dataset. Please share your feedback on the reward scheme, alpha score API, target choice, and any other aspects.
Let’s make DataCrunch crunchier together!
May the crunch be with you.