Approach
I’d like to detail my approach and share the validation results.
All validations results are calculated as an average from moon 50 to moon 268.
I used four types of models:
- LightGBM (CV 3.74) (100 features) (loss rmse)
- ExtraTreesRegressor (CV 3.65) (100 features) (loss squared_error)
- Catboost (CV 3.68) (89 features) (loss rmse)
- NN (CV 3.56) (89 features) (loss mse)
I selected the features with forward feature selection.
Validation and Results:
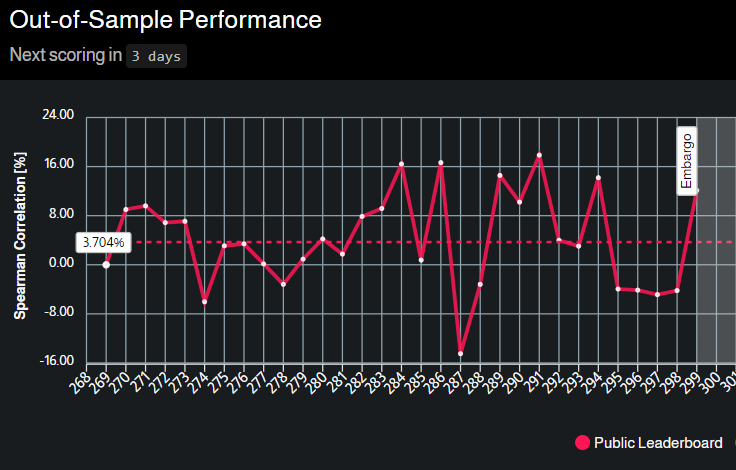
Through stacking these models I got CV 4.22 (LB 3.704).
Target transformation
np.log1p(target)
Extra features
Number of IDs in the previous moons
CV-LB consistency
I found that big improvements were reflected in LB but sometimes small improvements were not reflected due to certain degree of randomness that exists
Historical data and retraining
I found that just using last 10 moons for training gives the best results in my case, so I put 1 retrain every moon and the training data is the last 10 moons.
Observation on Randomness:
During the course of the competition, my best public submission (4.15 LB) was obtained inadvertently due to a bug in the code. This discovery sheds light on the presence of a certain degree of randomness inherent in the competition.