Thank you that explains that I could upload the weights and access them during the infer() from the resources/ directory.
But what you have not answered is the train() function. Do we get different training data during a run ? If not is it not better to do the training before and just submit the weight and the infer() logic ?
The train function is run only once, while the infer function is run for each file (data_file_path).
In the train function, you are supposed to read the data however you want (located in data_directory_path) to train your model. The function’s return value is ignored.
In the infer function, the returned value is a prediction for the current file and is used for scoring.
Thank you. That makes things a lot clearer now. One thing is still left: Are the training data in data_directory_path the same as we have already downloaded via the notebook ?
Thank you again. Last question please: That means, I can do the training on my PC and then upload the code for infer(), the model weights and leave the train() method empty ?
Hi, I have follow-up questions on the submission. I am planning to submit a notebook as the final product, and my questions are:
(1) I should use random-submission.ipynb as template, right? This means, there will be train(), infer(), crunch.test() functions in my submitted .ipynb file?
(2) Currently I am training the model locally. In the future, should I copy and paste these codes inside the train() function for submission? In addition, I would expect the output of this function is a trained model, but from the random_submission.ipynb, it seems that nothing is returned - could you clarify this?
(3) Finally, for the infer() function, based on its internal code, I don’t understand how it is using the trained model from the train() above, as it is not calling the train() function - could you comment more on this as well?
you could use train and infer for cloud,
and crunch.test for local testing purpose which will simulate the train() infer() on your local machine
when you test both train and infer functions on local machine you will see how it behave in cloud.
when train or infer functions used you may put any logic you want there, for example save the model trained in train function in /tmp/ folder and then load for inference in infer
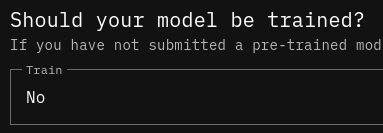
i do not use train , it is dummy , and it can be skipped if you select “No”
Just wnat to know this is the training data? and we need to use this data to train the model? after training the model , the models need to be saved at resources folder for each DC or UC? Still lot of confusion on how to use this for local testing? Can you please clarify on how the inference happens and infernce on which data?
@enzo Now I have trained locally and I stored all my model files in resource directory. Now when I am submitting the notebook with inference code. How does the model know my resources folder in my local machine when I submit a notebook (.ipynb)? Please clarify …As the models are locally in my machine. What to do? The first option : Do I need to submit the resources folder in zipped format to “Model Files (Optional”") or Option 2: If I run this code locally # Test the implementation
crunch.test(
no_determinism_check=True,
) the resources folder will automatically replicated or pulled into your server? Can you please help me to undersntand? @enzo thanks
Your infer function will called on each .zarr file that you need to predict.
Your model directory will always be available via the model_directory_path (list of parameters). Even when submitting a notebook.
When submitting files via “Model Files”, you need to select a directory that will be sent along with your code. Like this, you can include multiple files. No need to compress it.
Yes your model will always be downloaded in the runner before running your code.